Why Onshape?
Why Onshape?
As long as there have been applications that manage organizational data into a database, there has been a need to share that data between different departments and therefore, usually, different systems. In a typical design/manufacturing organization, there could be at least four or five mission-critical databases that manage the data for different departments and for different stages in the product’s lifecycle.
Initially, these systems provide the capabilities required by their consumers (i.e., the departments that use these systems). For instance, the Finance might use QuickBooks, Manufacturing might use a manufacturing planning and execution system (MES), Engineering might use a Product Data management System (PDM), and so on for each group in the organization.
This often leads to disparate silos of data and knowledge. The departments in an organization do not work in a vacuum; each is dependent on information generated by other groups. For instance, Manufacturing can’t produce accurate assembly instructions without input from engineering on the designs and the bill of materials. Finance can’t price the product without understanding its contents and which parts are manufactured in-house or purchased.
Therefore, the need to integrate these systems becomes critical for the organization to function optimally. Initially, connecting one system to another can be a straightforward process. This usually involves some services to get the systems to talk to each other, however it isn’t too painful as long as the requirements are clearly defined.
Anyone who has implemented integrations between PLM (Product Lifecycle Management) systems or ERP (Enterprise Resource Planning) systems will tell you of the nightmare scenarios they encountered. Often this is the result of poorly scoped and defined requirements, conflicting requirements coming from multiple departments, and the many integration points required between systems. The result is that the organization is not getting what it wants or needs, the customer is paying for services that do not provide the promised solution, and usually the project is long overdue. All this equals an unhappy customer and often the software vendor’s solutions are blamed for the disaster.
Over the years, many technologies have appeared (and some of them, just as quickly disappeared) to enable integration without the need to write thousands of lines of custom code that needs to be re-written for every software upgrade. Several technologies provide “codeless” integration between SaaS products (Zapier, for example). These solutions are particularly good for generic use cases for data exchange between systems, but can be limited when it comes to custom modifications to the data being sent that might be required by a specific customer. In addition, they have the overhead of requiring a subscription to their service. Sending corporate IP through another third-party can also cause data security issues.
Therefore, we can understand that in most organizations integration between systems is a necessary evil that must be tackled, either with an out-of-the-box solution or through some custom coding.
Early on, Onshape understood that as an engineering system, it cannot exist in a vacuum; it must be able to communicate with other systems. For this reason, the REST API was developed.
An API, or application programming interface, is a set of rules that define how applications or devices can connect to and communicate with each other. A REST API is an API that conforms to the design principles of the REST, or representational state transfer architectural style. For this reason, REST APIs are sometimes referred to RESTful APIs.
Onshape SaaS
Onshape was built from the ground up as a true SaaS-based system; Onshape had no investment in legacy code and was able to develop an application that truly runs as a multi-tenant SaaS solution from the first line of code. Many companies claim to run cloud-based solutions, but since they have such a large investment in their legacy code, that they can’t just discard and start again from scratch. Instead, they tend to try and port that code to the web.
More often than not, porting existing code to the web and calling it a SaaS solution is no more than a marketing ploy; it isn’t a true SaaS solution if it wasn’t written as one. These are generally known as cloud-hosted solutions. This means that a typical three-tier data management solution (which could have previously been installed on a set of servers), has now been modified to be hosted on the web.
Traditional three-tier architecture
Traditional PLM systems typically use a three-tier architecture, mainly consisting of an application server, a database server, and a client (either a web client or a thick client installed on the client hardware).
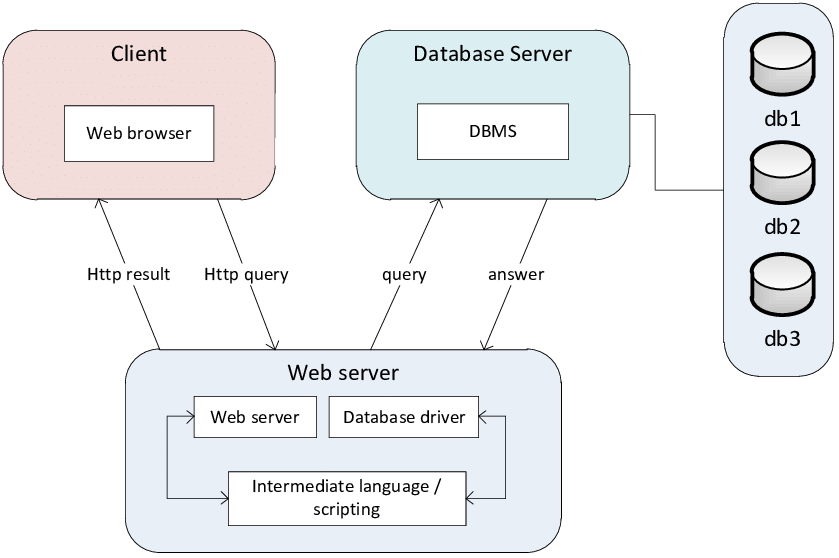
Typical three-tier architecture
To connect to and integrate with this architecture, APIs are usually exposed on the application or web server. If this architecture is ported to the web, it cannot make customizations through the API, since it would modify the behavior of the program for everyone connected to that application server.
Single- vs multiple-tenant architectures
The three-tier architecture is typical of most PLM solutions on the market today, which is fine if you want the solution to be installed on company servers and be accessible to people within the company only.
When this type of solution is ported to the web, software vendors typically must create a single-tenant application where an application server and a database server are provisioned for each new customer.
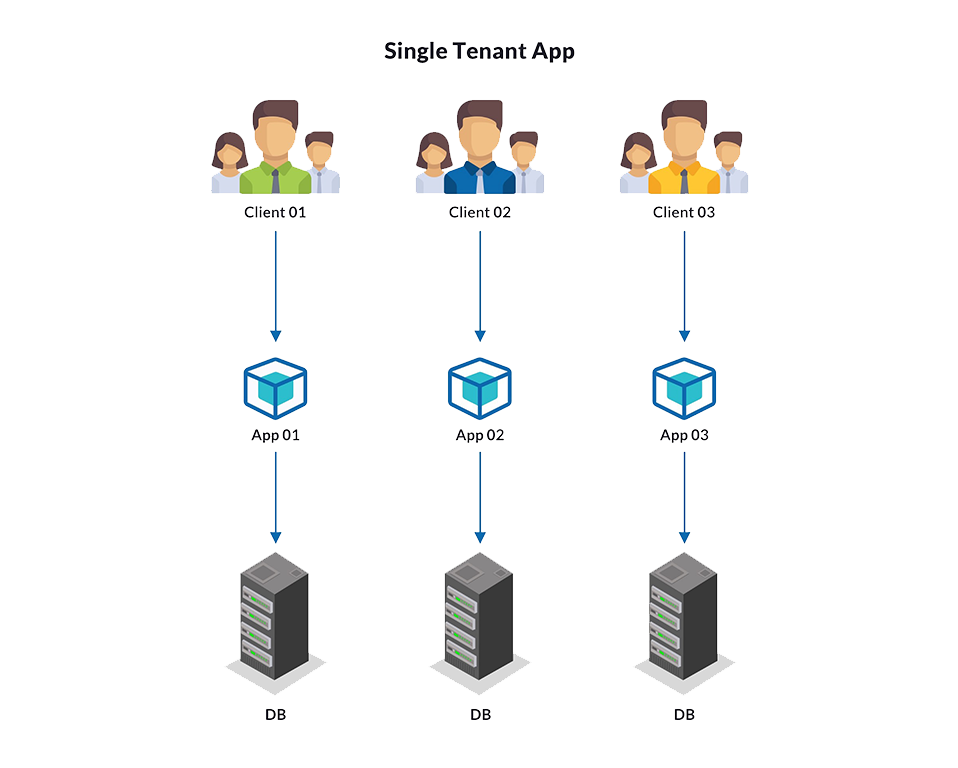
Single-tenant architecture
In this case, the vendor must use expensive hardware to host more customers, which is not a sustainable model.
Modern 21st century software solutions use multi-tenant solutions that can be hosted on services such as Amazon cloud, Azure, etc. There are many benefits to this architecture, including that servers can be provisioned and decommissioned on the fly to provide ultimate performance whenever required. Since servers cost money, decommissioning servers when they are not required is a key benefit to a true SaaS solution.
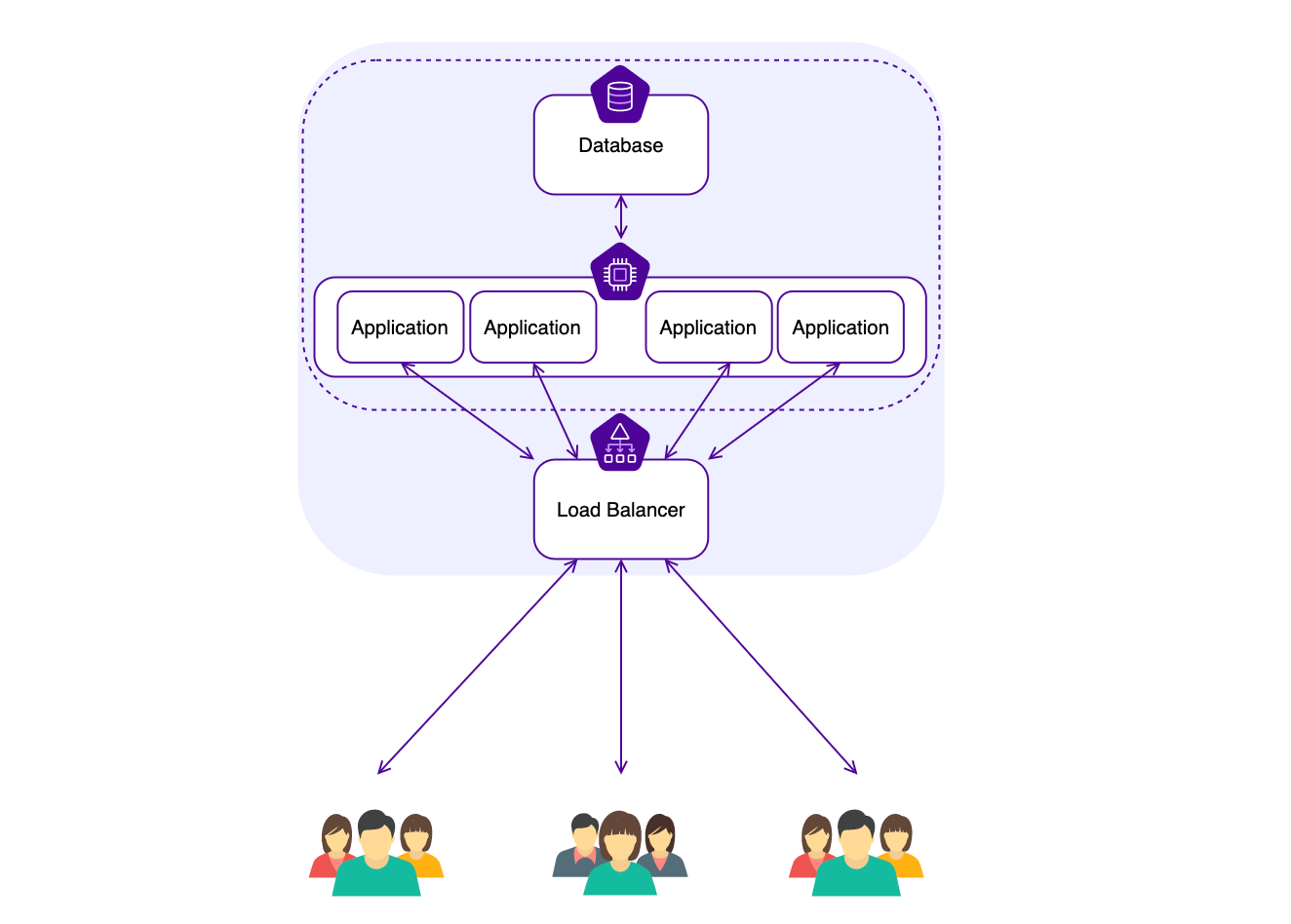
Multi-tenant architecture
Since each application is separate in this architecture, we can enable customizations that can’t be implemented in a single-tenant architecture. For example, we can provide access to the REST APIs that are required for Onshape integration. In the single-tenant architecture, if you provide API access to the application server, one customer will be modifying that application for all customers who are registered on that tenant.
The Onshape Difference
Onshape does not work like other legacy CAD systems. Onshape was built from scratch for the cloud and as a modern CAD system, so many of the failings of legacy CAD systems were excluded.
There are many differences and benefits to Onshape, which are well-documented in the Onshape Help and training materials.
The information in this section is specific to integrations, since Onshape does not behave like a traditional file-based systems. When writing an integration for Onshape, it is critical to understand the nuances in Onshape’s design practices and how data is organized in Onshape.
Data-driven/fileless
Most traditional PDM/PLM systems integrated with CAD systems enable this integration on a per-file basis. This means that you have an object in the PDM/PLM system that corresponds directly to a file in the CAD system. In this way, the PDM/PLM system can manage access to the files, build assemblies from the files, view the CAD data, and much more.
Onshape, however, does not work this way.
Being data-driven means that Onshape has no files, just data, so an integration into Onshape is going to look different from any integration to a CAD system that you might have done previously.
In traditional CAD, a single file represents a snapshot of what the design looked like at a specific moment in time. Unless it’s changed, it will remain in that state forever. PDM systems manage these files, and once a designer decides to make a revision or a release, the file is locked, and a new file can be created to represent any further updated versions or releases of the design. PDM/PLM systems are very good at managing this data in an up-to-date structure, but it does have the drawbacks. They generate many file copies of a specific design, and once a file is taken out from the system (for instance, to share with a supplier), it is no longer managed and tracked.
Onshape uses data instead of files. The data is always up-to-date and can be collaborated on in real-time without the need to send file copies back and forth. This means that Onshape views versions and releases differently than those traditional systems do. When integrating with Onshape, we must design for data rather than files.
Files can be generated from the Onshape data. For example, you can generate a PDF of a drawing upon release or of a STEP file that can be used by other downstream systems.
A key benefit of a data-driven system is the ability to retrieve detailed, real-time analytics. Onshape has comprehensive analytics; including who can view or edit a design, when and exactly what edits are made, which commands were used, and how long was spent modifying the design.
Built in PDM
Up until now, CAD was one software program, and PDM/PLM was another program that had to be integrated with the CAD. In many cases, both programs could be sold by the same software vendor (even though there are many PLM systems available that are sold by independent vendors who have no CAD system). Regardless, a PDM/PLM system always had to be an added solution to the CAD system.
No matter how deep the integration between a CAD system and a PLM system, there is always the need to sync data between the two. This is usually a weak point in any solution that is prone to errors.
Being data-driven, Onshape already has PDM built in as part of the CAD system. This is unique in the industry: CAD and PDM as part of the same solution with no additional piece of software required.
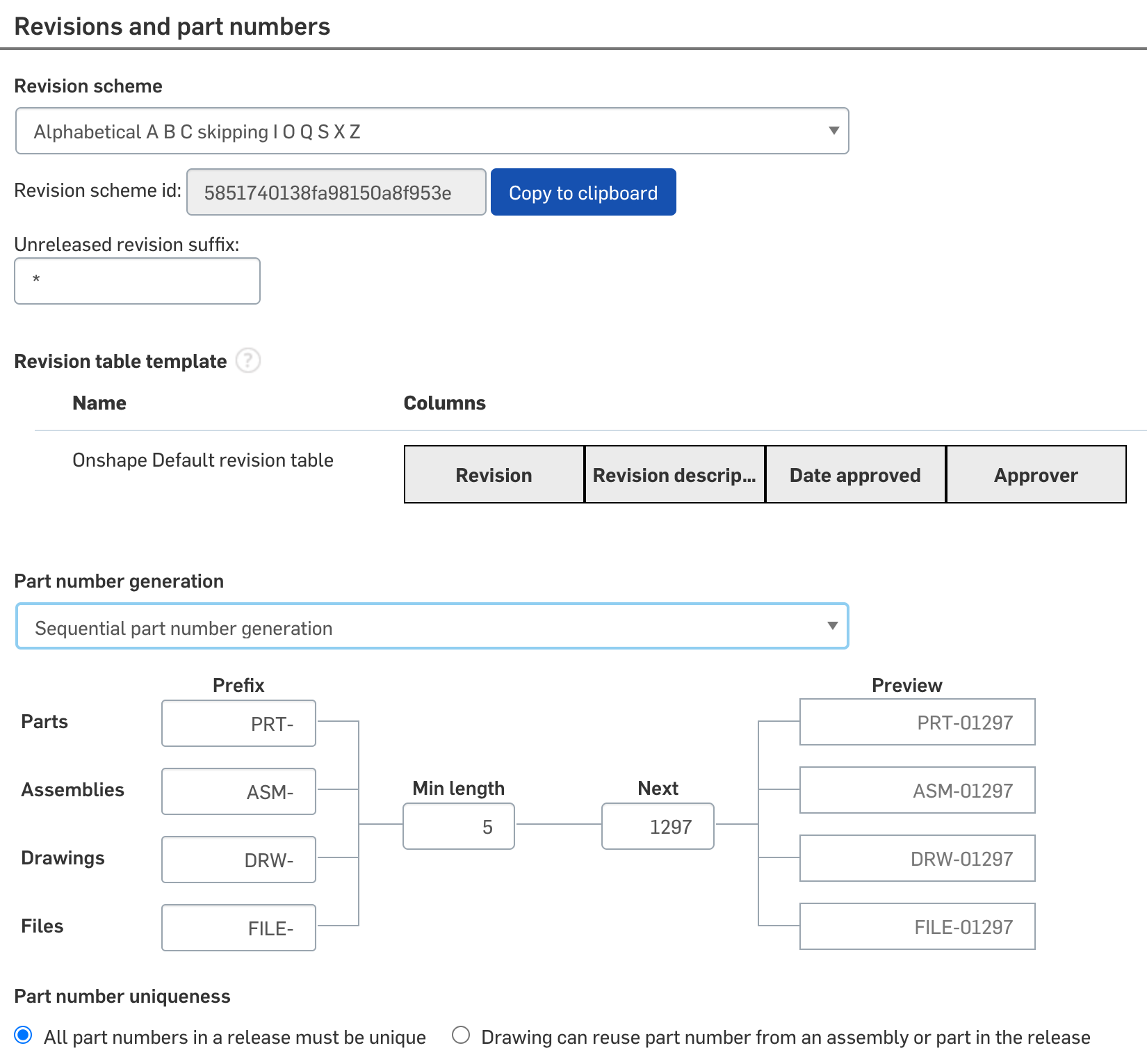
Onshape’s revision and part number schema definition interface
For instance:
Since the data is always up-to-date, the correct state of any design is always represented in real-time with no delay for syncing between systems.
Unlike file-based systems, the data is never locked; it is always available and always changing.
PDM system data management aspects are fully integrated into every aspect of the CAD system.
True real-time collaboration/co-design on both design and data is enabled.
So, what does this mean when it comes to integrating Onshape with another PLM system? First and foremost, we must understand that there are many things that a PLM system does that Onshape’s PDM capabilities can’t do. Integrating Onshape to a PLM system should augment the powerful capabilities already available inside Onshape, not necessarily replace them. Similarly, Onshape does not replace PLM-native capabilities. Instead, depending on the business case, we can use the best-in-class capabilities of each system to augment the other.
The Onshape release process is an example of the augmentation of each system’s capabilities. Onshape has a specific way of managing the release of data that is different from traditional PDM systems. This capability is inherently suited to a data-driven approach and provides a lot of value to the update of design data in Onshape. At the same time, PLM systems provide enterprise release processes that may include many people and different departments that extend beyond the engineering domain. Such PLM processes can be highly customized and suited to the organizations established business processes.
In this scenario, it doesn’t make sense to avoid the enterprise release processes in the PLM system. However, also omitting Onshape’s release capabilities could put data between Onshape and the PLM system out of sync and prevent Onshape from updating data (e.g., watermarks and title blocks on drawings, icons related the visualizing the state of data, etc.).
In this case, we want to use the best-in-class features of each software solution without compromising the capability provided by each solution. If we plan our integration correctly, this can be achieved by initiating the release of the data in Onshape, transferring the release data to the PLM system where the release process will be triggered, and finally automating the release in Onshape once the process has been completed in the PLM system.
Multi-part Part Studios
In traditional CAD systems, one file typically equals one part. While design-in-context is available in most CAD systems, and multiple solid bodies can be created, each part is self-contained in a separate file. For PLM systems, this makes it easy to associate an object in the PDM/PLM database with a specific CAD file. This is not the case in Onshape.
In Onshape, parts are designed in what’s called a Part Studio. Within a Part Studio, the designer is free to create as many parts as they want. The general rule is that the parts should be related to each other in a system, thereby making it easier to design one part from another, however there is a lot of flexibility in how the designer wishes to work.
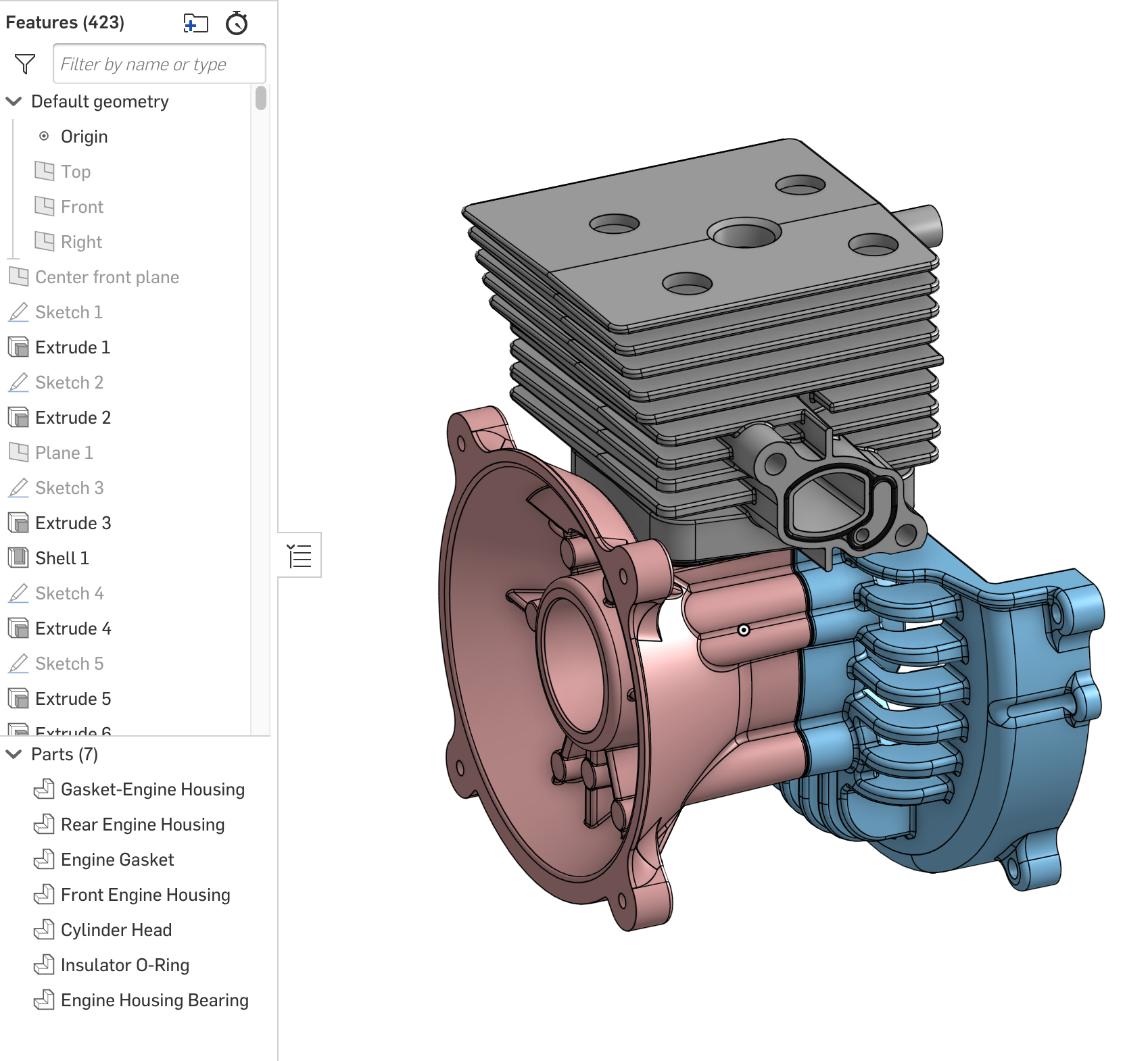
An example of a multi-part Part Studio in Onshape
The structure of the Onshape document is discussed in detail in the Onshape Architecture page. The Part Studio is included in an Onshape document.
We can already begin to understand that the traditional CAD/PDM paradigm of “one file per object” will not work with Onshape; the designer would be forced by the PDM/PLM system to only create one part per Part Studio. This would therefore limit the designer’s freedom for creativity in Onshape and seriously reduce the powerful functionality available for the designer to use.
Therefore, we need to re-think how we integrate with Onshape versus how we integrate with traditional CAD systems. Fortunately, Onshape’s REST API supports the multi-part Part Studio scenario. Instead of associating a file with an object in the PDM/PLM database, we now use the REST API to associate a Part with its corresponding object.
Versions and releases
Traditional PDM/PLM systems provide design release support by locking a CAD file for access. The access controls are defined in the database and the definition of a part/assembly/drawing as released is controlled by the database. When a new revision of the part is required, a file copy is made, and the database provides access to the new copy. Generally, the old copy representing the previous release persists in the file store and can be referenced by the database. This is not how Onshape works.
 Since there are no files in
Onshape (just data) no file locking or copy mechanisms are
available. Instead, Onshape looks at the data as a continuous timeline
that is always moving forward and always changing as the design evolves.
The data is never locked; it is always available.
Since there are no files in
Onshape (just data) no file locking or copy mechanisms are
available. Instead, Onshape looks at the data as a continuous timeline
that is always moving forward and always changing as the design evolves.
The data is never locked; it is always available.
In place of file copies that represent versions and releases of the design, Onshape provides the ability to create versions as bookmarks in the timeline. When creating a version, Onshape places a bookmark in the timeline that represents the state of the design at that specific moment in time. Releases work in a similar way, but they are defined as official, company-approved processes and have special meaning.
In addition to creating versions and releases, Onshape can create branches, which can be defined as alternative timelines. A designer might want to experiment with alternate design ideas without modifying the existing design that others are working on. By creating a branch from any point in the timeline, the designer is free to experiment with alternate ideas. If the ideas work, they can be merged into the current timeline at any point.
From an integration perspective, we need to take into consideration how Onshape works with versions and releases. Since a release represents a company-approved design, Onshape provides processes for the approval of a release and the change of state of a design. Onshape also provides APIs and triggers (events) that enable integration points throughout the release process. It is through the triggers and the APIs that integration of any third-party system that wishes to manage the release process is enabled.
Workflows
Release and obsoletion workflows are included with Onshape and can be customized to meet company standards.
For details on how to implement and customize Onshape’s workflows, please review these online help topics:
Most PDM/PLM systems can model a company’s business processes in a workflow. These can be highly automated processes that move data and file references through a process of reviews and approvals. Onshape also has this capability, which is currently used for release and obsoletion processes.
There are no files or file references in Onshape that are moved through the process. Onshape only has data. Therefore, it is the data that is referenced at each stage of the process. Traditional PDM systems might make file copies and lock files as they move through a release process. If the process is rejected at any stage, those files must be discarded, the previous version of the files unlocked and all states updated. In short, it system must rewind back to the state of the files and the data when the workflow was initiated. This is a lot of complex actions that must occur when a process is rejected for any reason. Onshape doesn’t work this way.
A release process can be started on data (such as assemblies, parts, drawings, etc.). For example, if the state of a referenced part is updated to “Pending,” and the process is rejected at any stage, there is no rewinding of files and data; the data just reverts to the original “In Progress” state, and the workflow is discarded. Since the workflow didn’t complete, nothing related to the data has actually changed. When you are used to traditional PDM systems, this feels like an anti-climax, and we often receive the question, “But where’s my process? Where’s the data that was attached to the process?”. Well, the answer is: nothing changed. Until the process is completed, nothing actually changes, so the data is in the same state it was prior to the initialization of the release process.
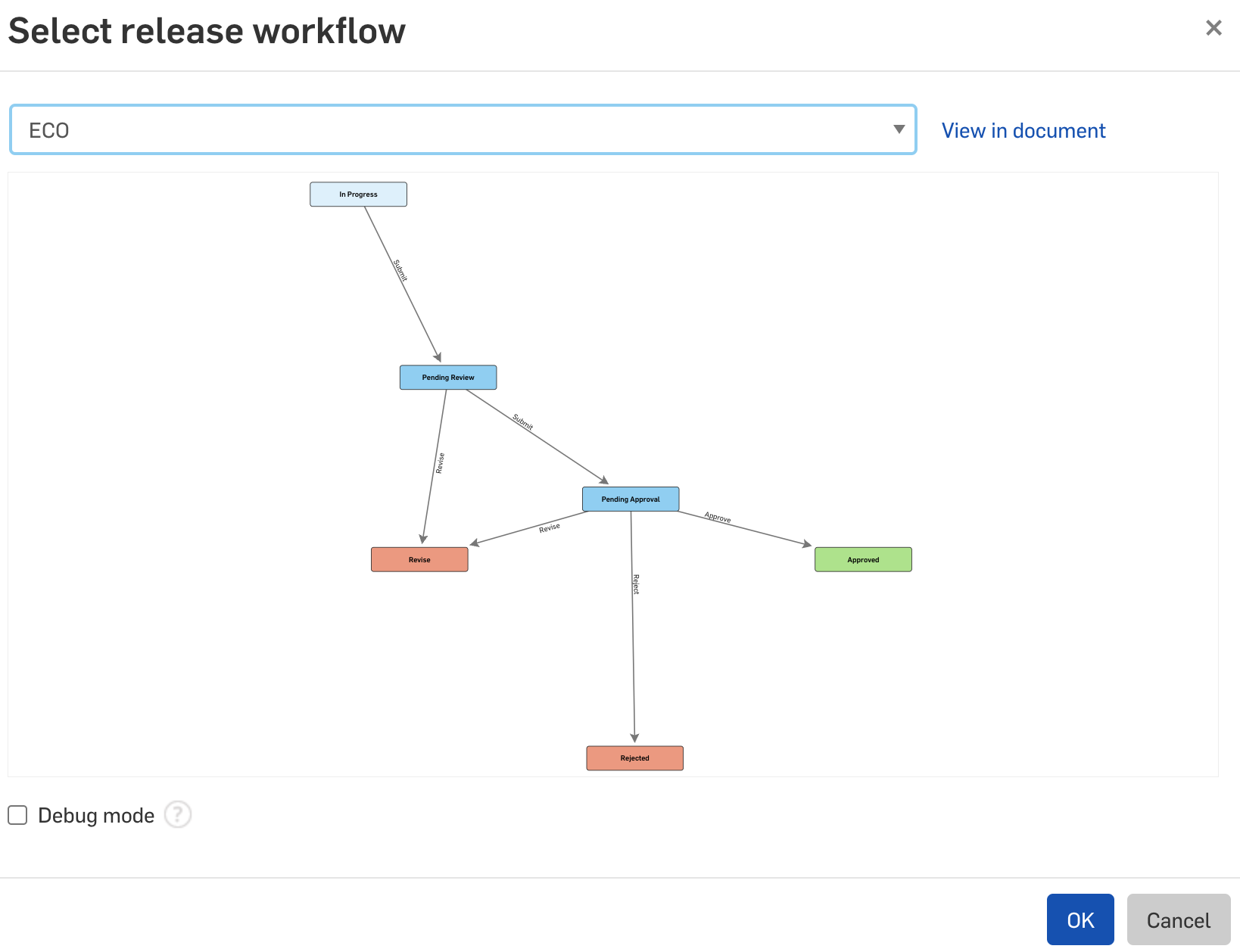
A custom release process in Onshape